医療統計で使われる分散分析(ANOVA)について
医療統計でよく出てくる統計手法に分散分析があります。分散分析の英語での名称はANalysis Of VArianceです。 大文字部分をとってANOVAとも呼ばれます。
例えば、降圧剤の試験で、薬の種類や投与量を変えて血圧値を測り、効果を見たい場合などに使われます。プラセボと薬A、薬Bなど薬の種類のみを変える時、データの値を変化させる原因(変数)は1つとなります。このような分散分析を一元配置分散分析(one-way ANOVA)といいます。薬の種類と投与量を同時に変化させる場合は、二元配置分散分析と言います。 一元分散分析も二元分散分析も考え方は分散分析として同じです。
分散分析の考え方
分散分析の利点は、多群の比較ができることです。t検定では2群までしか比較できませんが、分散分析では、3群以上の比較に用いられます。上記の例だと薬の種類を複数種類(3種類以上)一度に検定できます。2群の場合はt検定でも結果が同じになるので、通常は用いられません(わざわざ使う必要がありません)。t検定の多群への拡張が分散分析と考えることもできます。
t検定が平均値と標準誤差から説明できることを下記の著書により説明しましたが、分散分析も同様の考え方で、有意差を説明できます。
医療統計入門 iBooks版(購入はこちら)
医療統計入門 Kindle版(購入はこちら)
分散分析法のネーミングが直感的な理解を妨げているように思います。これは歴史的な経緯もあります。1918年に『The Correlation Between Relatives on the Supposition of Mendelian Inheritance(メンデル遺伝の仮定における親族間の相関関係)』という論文で、ロナルド・フィッシャー(Ronald Fisher)が「分散」という用語(概念)を使ったのが始まりです。その後、1925年にフィッシャーが『Statistical Methods for Research Workers(研究者のための統計学的方法)』に分散分析法を載せたことで、広く知られるようになりました。最初に分散(の概念を用いること)に気がついて「分散」分析と言ってしまったのですが、分散を分析するのではありません。分散を用いて、多群の平均値とバラツキを分析する手法が分散分析法になります。
分散分析は、「2つ以上の群の中の標本が同じ平均値を持つ母集団から取られた」という帰無仮説を検定」するための方法であり、具体的にどの群とどの群の間に差があったかを知るためには、多重比較を行う必要があります。
もう少し口語的に書き直すと、検定の結果「薬の種類を変えたとしても降圧効果に差がなかった」とはどうも言えない場合(きっと何か差がある!有意差あり)でも、どの薬のために結果が変わったのかは分からない、となります。
分散分析における数式の見方
「医療統計入門」では、数式を使用せずに説明をしましたが、こちらでは少し数式を扱いたいと思います。
医療統計入門 iBooks版(購入はこちら)
医療統計入門 Kindle版(購入はこちら)
話がややこしくなるので、プラセボ、薬A、薬Bの3群(a=3)を比較をする一元配置分散分析で、かつ、理想的な場合を想定して、各群の試験回数はn回で共通とします。(途中でデータが取れなかったりすることがなく、綺麗なデータが取れたとします。)
その時にF値は下記のように表せます。

分散分析では、効果(によって説明される平均平方)を分子、誤差(によって説明される平均平方)を分母とすることでF値を計算します(F検定)。
具体的に見ていきます。統計においては、数値の大きさを比較したい場合に、符号の絶対値ではなく、2乗することがあります。
|-1| < |2| < |-3| (絶対値の大小)
(−1)2 =1
22 =4
(−3)2 =9
1 < 4 < 9 (2乗の大小)
Σは和を取るということなので、aiとeijが何を示しているのかが分かれば、分散分析の数式で何が比較されているかを理解できたことになります。
結論を言うと、aiとは全部の群の平均値から各群までの平均値の差になります。 eijは各群の平均値から試験された個別のデータまでの差になります。 言葉で説明されるより図を見ていただいた方が理解しやすいと思います。
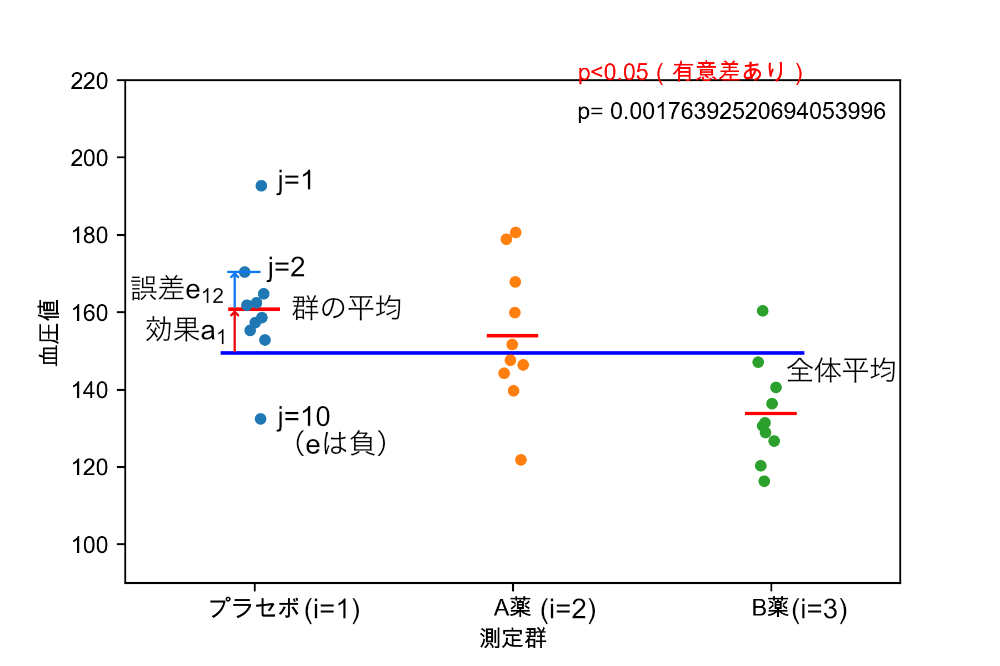
νaは自由度(群間)、νeは自由度(残差)になります。自由度は群数や試験回数(データ数)で表される補正値になります。
νa = 群数(a)-1
νe = 群数(a)×(試験回数(n)−1)
具体的にデータがどのような平均値、バラツキを持った時に有意差が出るのかについては、著書の方で説明しておりますので、ご参照ください。


(関連コンテンツ)
医療統計学が難しい理由
現場で役立つ医療統計スキル習得のための最短経路
臨床論文に出てくる試験デザインの分類と種類
文献によく出てくるt検定の種類、3つ。
検定の多重性について
標準偏差が分かるための正規分布。確率分布を理解して疑問を解決。
サブグループ解析でのハザード比(HR)の読み方
カプランマイヤーなどの生存時間解析で試験の背景比較がよくない訳
どれをインストールしたらいい?医療で使える統計解析ソフトウェア6選
電子書籍「医療統計入門 〜統計の基礎からt検定、 分散分析(ANOVA)まで〜」(iBooks/Kindle)